
Members of the SFB TRR 161 have recently participated in an “Workshop on Crowdsourcing” at the University of Konstanz. The organizers, Franz Hahn and Vlad Hosu, introduced the use of CrowdFlower for quantitative user-studies. The intention was to get participants familiar with the platform and the basic concepts of crowdsourcing for user studies. All participants were able to design and run their own hands-on experiment, to get a better feel of the challenges and benefits of crowdsourcing.


An interview with Vlad Hosu I got a deeper insight into the topics and aims of this workshop and the research activities with crowdsourcing.
Claudia Widmann: Why did you do the workshop?
Vlad Hosu: The SFB TRR 161 is called “Quantitative Methods for Visual Computing”. There’s an emphasis on empirical evaluation of results e.g. user-studies. Crowdsourcing is an online alternative to in-the-lab user studies. However, it’s often easier to deploy: on-demand, inexpensive and scalable. There are concerns about the crowd-worker realiability, which I believe is the main limiting factor to a wider adoption.
Claudia Widmann: Why do so many other scientists of the SFB-TRR 161 want to know about crowdsourcing?
Vlad Hosu: We’ve gotten good results using this medium before, and it has some very nice benefits over traditional lab-based studies. Probably many have heard about it, but didn’t get to experience it first-hand. This was a good opportunity to do just that, run their first experiment in the crowd.
Claudia Widmann: Were there participants who already used crowdsourcing and had special questions that could be clarified in the workshop?
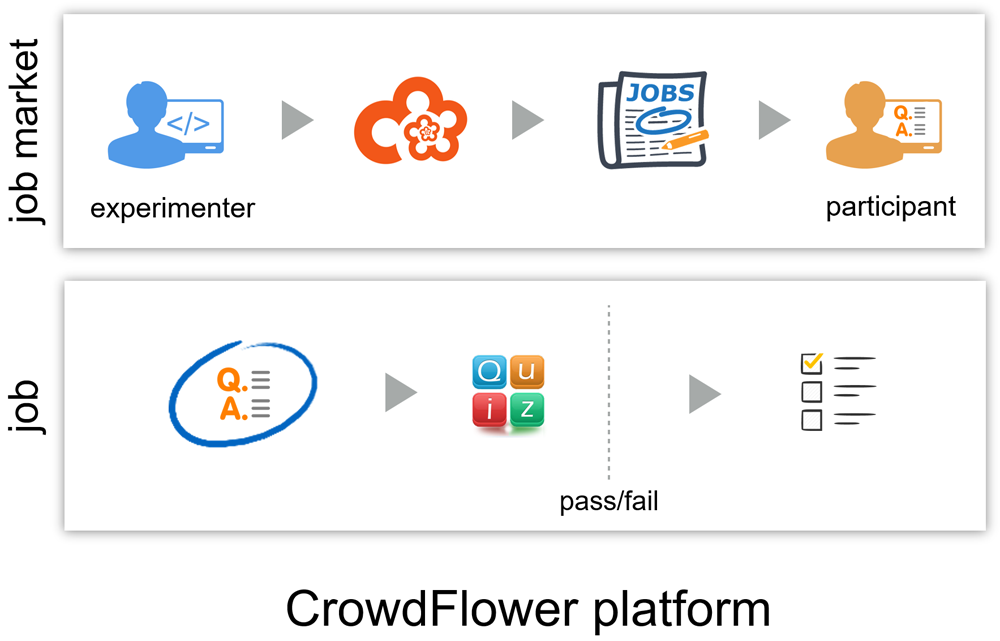
Vlad Hosu: There are multiple crowdsourcing platforms out there, each one having its own set of feature, community dynamics, etc. Some of the workshop participants have used crowdsourcing before, but were not familiar with the particular platform that we’ve been worked with: CrowdFlower.com.
Claudia Widmann: What are the difficulties of the research with crowdsourcing? Can you not just set up an account, define the job and go?
Vlad Hosu: Crowdsourcing is not applicable, at least not in the same way, to everything that lab-based user studies are. For instance, crowdsourcing involves annonymous participants, which are paid little, don’t have a vested interest in the experiment and oftentimes don’t put in an honest effort to complete their designated task. The research in this field relates to getting the best results from a crowd experiment, in terms of improved reliability, reduced costs, methodologies for addressing various data requirements, and so on.
Claudia Widmann: Is crowdsourcing getting more and more important for research in the future?
Vlad Hosu: Crowdsourcing is a general idea, say, Wikipidia is a type of crowdsourcing platform as well. In this sense, crowdsourcing is definitely becoming more important for the industry and also for the research community. What we covered in the workshop is a general-purpose experimental platform (CrowdFlower), applicable in particular to data annotation such as tagging, scoring, etc. There are several initiatives that aim for better crowdsourcing experimental standards, and this is a good indicator of it maturing as a research field. Personally, I think crowdsourcing as an annotation methodology is definitely going to be used more in the future. We need lots of input for our data-hungry learning machines and crowdsourcing is a scalable way to get it.
Claudia Widmann: What was the talk of Babak Naderi about?
Vlad Hosu: Babak presented a more in-depth view on crowdsourcing as a research topic in itself. He emphasized the importance of understanding the motivation of crowd-workers. This helps with the design of better crowdsourcing experiments (reliability, costs), but also setting the right expectations for the quality of the experimental results.

Claudia Widmann: What was the feedback of the participants? Will they use crowdsourcing now? Or is it not practicable for their research?
Vlad Hosu: Some of their worries about crowdworker reliablity have been dispelled. Many have had good results with their first hands-on crowdsourcing experiment (their own topic and data). Some of the topics of the experiments included colorfulness of food photos, clustering annotation in scatter plots, building category classification, evaluating the greyscale levels in stippled images and the annotation of specularities in images. The preliminary results of these studies are promising, and some of the experiments will be extended in later publications.
All in all, the workshop seems to have succeeded in getting our participants started with crowd experiments, which was the original goal.


